Tässä on mielenkiintoinen tuore artikkeli. Ajatuksena pyrkiä testaamaan sitä, missä määrin LLM:n osaaminen perustuu muistamiseen ja missä määrin asioiden todelliseen konseptuaaliseen ymmärtämiseen. Testisetuppina toimivat yksinkertaiset ohjelmointitehtävät, jotka suoritetaan poikkeuksellisesti harvinaisilla ohjelmointikielillä, joista on varsin vähän repositoryja opetusaineistossa.
Kyseinen artikkeli on mielestäni aika harhaanjohtava eikä varsinkaan ei-koodareille välttämättä aukea mistä on oikeasti kyse. Tutkimuksessa annetaan ymmärtää että siihen valittiin harvinaisia ohjelmointikieliä, mikä toki on puoliksi totta. Toinen puoli totuutta on, että kyseiset ohjelmointikielet eivät edes yritä olla käytännöllisiä, vaan osa on tehty vitsillä ja osa ihan vaan tarkoituksella hankalaksi koodata. Tästä taas seuraa se, että tehtävät kuten “summaa kaksi lukua” ovat täysin eri vaikeustason tehtäviä kun ohjelmointikieli vaihtuu Pythonista Brainfuckiin. Kyse ei siis ole pelkästään uudesta syntaksista. Esimerkiksi ihan perus “hello world” on Pythonilla kirjoitettuna 1 komento kun taas Brainfuck ratkaisu on 106 komentoa.
Moni on tehnyt artikkelista tällaisia tulkintoja, mutta koska artikkelista puuttuu ihmisbaseline kokonaan, ei siitä voi mielestäni tehdä tällaisia päätelmiä. Pidän erittäin epätodennäköisenä että ihmiskoodarit pärjäisivät vastaavassa ympäristössä merkittävästä paremmin. Kielimallit olivat huonompia ratkomaan vaikeita tehtäviä, ihan kuin ihmiset.
En nyt välttämättä sanoisi harhaanjohtavaksi kuitenkaan. Esimerkiksi tuo Brainfuck on käytännössä 8-bitin alkioita sisältävällä nauhalla operoiva ohjelmointikieli, joka sisältää 8 komentoa: Nauhaa voi kelata, alkioiden sisältämää dataa voi muokata lisäämällä / vähentämällä alkioihin arvo 1, syötettä voi lukea ascii-merkki kerrallaan ja samoin tulostaa. Lisäksi looppaukseen / hyppyihin on käytössä kaksi komentoa.
Toki tässä tapauksessa uuden syntaksin mukana tulee suppeampi työkalupakki liittyen siihen, mitä ohjelmointikielellä voi suoraan tehdä. Tästä johtuen (ainakin näin ihmisen näkökulmasta) tuohon vastauksen tuottamiseen brainfuckilla liittyy kaksi selvästi erillistä vaihetta:
Varsinaisen tehtävän ratkaisualgoritmin muodostaminen jollain sopivalla abstraktiotasolla
Brainfuckin tarjoamien komentojen avulla sellaisten peruspalikoiden rakentaminen, joiden avulla ratkaisualgoritmi on tarpeeksi suoraviivaista muuttaa brainfuckiksi.
Sehän tuossa koko artikkelissa kai oli ajatuksena, että irrotetaan mallien muistelemat asiat ymmärtämisestä. Jotenkin tällä tavalla se kai täytyy tehdä, jotta mitään 1:1 käännöstä esimerkiksi pythonista ei voi suoraan tehdä. Toki tässä epäonnistuminenkin voi tapahtua sitten joko ratkaisualgoritmin rakentamisessa tai sen mappaamisessa uuteen ohjelmointikieleen ja sen mahdollistamiin toimintoihin. Epäonnistuminen ilman tarkempaa analyysia ei vielä ota kantaa siihen, kummasta syystä virhe johtui.
En olisi niinkään varma, ellei sitten rajoitu siihen mielikuvituksettomaan ratkaisuyritykseen, että yrittää suoraan kirjoittaa ratkaisun brainfuckilla. Tällöin varmaankin aivoille tapahtuu juuri se, mitä ohjelmointikielen nimi antaa ymmärtää.
Pykälän käytännöllisempi ratkaisu voisi olla esimerkiksi pienen skriptikielen kehittäminen, johon sitten voi rakentaa brainfuck kääntäjän. Skriptikieleen jos rakentaa tuen muutamille eri kokoisille kokoinaislukumuuttujille, taulukoille, mahdollisuuden tehdä funktiokutsuja, kirjoittaa silmukoita ja rakentaa yksinkertaisia ehtolauseita sekä suorittaa yksinkertaisia aritmeettisia laskutoimituksia, niin tämän jälkeen taitaa tuo tehtäväpaletti olla kohtuudella ratkaistavissa varsin “pseudokoodimaisella” skriptaamisella. Ja tehtäväsetin tarkemmalla analyysilla voi päätyä siihen, että vähempikin toiminnallisuus skriptikieleen riittää. Esimerkiksi funktiokutsuista voi mahdollisesti luopua ja silti tehtävät on kohtuullisen selkeällä tavalla ratkaistavissa. Kaikki tämmöiset mahdolliset rajaukset tietysti vähentävät kääntäjän rakentamiseen tarvittavaa vaivaa.
Tässä tapauksessa tuo skriptikieli + kääntäjä -kombo on siis se “peruspalikoiden rakentaminen” ratkaisua varten. Kääntäjän toteuttamista varten pitää toki harrastaa jonkin verran brainfuckailua, jotta saa yksinkertaiset palaset (esimerkiksi brainfuckin nauhapointterin tilanhallinta, datan kopiointi, aritmeettisten operaatioiden peruspalikat, globaalin datan hallinta nauhalla, mahdollisesti joku pino funktiokutsuja ja lokaaleja muuttujia varten jne.) generoitua sopivasti. Mutta tuo ehkä pitää brainfuckailun kohtuullisen minimissä sitten kuitenkin.
Jos jossain vaiheessa löytyy muutama vapaa ilta aikaa testailla tällaista, niin täytyypä ottaa työn alle. Näin äkkiseltään suhtaudun kuitenkin varsin positiivisesti siihen, että tuo tehtäväsetti olisi tämän kaltaisella lähestymistavalla kohtuudella ratkaistavissa. Nollatyöllä se ei tietysti lähde, mutta tuskin tuo mikään tekemätön paikkakaan on.
Ja vastaavalla konseptilla tietysti voisi ratkaista noita muitakin esoteerisia kieliä.
Mutta tämä on juuri se skenaario mitä tutkimuksessa mitattiin. Jos sitä vaaditaan kielimallilta, niin tietenkin sitä pitää vaatia myös ihmiseltä. Tai muuten tehdäkseen johtopäätöksen että mallit eivät kykene “yleistämään algoritmista ajatteluaan”, täytyisi tehdä johtopäätös ettei ihmisetkään pysty.
Olet täysin oikeassa, mutta jos tämä sallitaan, myös kielimallit ratkaisevat kyseiset tehtävät. Myös artikkelin kirjoittaja on tiedostanut asian X puolella.
For the nth time, we were measuring model performance under constraints (such as zero-shot/few-shot or without tools). As we mentioned in the original thread, if you give recent models tools and lots of tokens, we’re observing they solve these problems and that’s a research we’re continuing with
Tässä esimerkiksi ChatGPT ratkaisemassa yhden “extra hard” tehtävistä: https://chatgpt.com/share/69bd3015-f7e4-8009-9dc7-d6ced755c132 Mainittakoon vielä että tuossa mainitsemasi kaltaisen kääntäjän kirjoittaminen oli kielletty, mikä vaikeutti tehtävää. Ja on selvää että jos siirrytään sieltä ChatGPT puolelta johonkin koodaamiseen suuniteltuun ympäristöön (Codex, OpenCode, etc), mallit suoriutuvat vielä paremmin.
Kokeilin vielä ihan huvin ja urheilun vuoksi miten nuo tehtävät ratkeaa ilman kyseisiä rajoitteita kunnon työkaluilla. Otin kaikki 20 extra hard tehtävää ja jaoin ne näiden kielien kesken. Sen jälkeen annoin Claude Coden (Opus 4.6) toteuttaa. Ainoa asettamani rajoitus oli että web haku ei ole käytössä. Tulokset olivat odotusteni mukaisia:
Brainfuck 100% (5/5) - X04, X09, X10, X16, X17
Befunge 98 100%(5/5) - X01, X02, X05, X06, X12
Whitespace 100% (5/5) - X07, X13, X18, X19, X20
Shakespeare 100% (5/5) - X03, X08, X11, X14, X15
Unlambda 0/0*
Tutkimuksessa käytetyssä Shakespeare tulkissa oli bugi, jonka takia jakolasku ei toimineet specin mukaisesti. Claude löysi bugin ja löysi kiertotien vaikka tulkki ei toiminut kuten pitäisi. Benchmarkin kaltaisessa zero-shot/few-shot skenaariossa on käytännössä mahdotonta löytää kiertotie tuollaiselle bugille.
Unlambda testit jäivät nyt tekemättä, sillä tutkimuksessa käytetty Unlambda tulkki ei tue syötteen lukemista ollenkaan. Näin ollen vain 2 helppoa tehtävää on ratkaistavissa ja loppuja on mahdoton ratkaista.
ARC-AGI-3 benchmark julkaistu. Mallit skoraa jotain 0.3% hujakoilla ja ihmiset 100%. Ei toki kaikki ihmiset, mutta vähintään kaksi ihmistä on ratkaissut joka tehtävän. Tyypillinen ratkaisuaika vähemmän kuin 20min. Myös paperi kannattaa lukea siinä kuvataan mukavasti mallien kehitystä.
Uutuutena on että kyseessä on vuoropohjainen peli. Toinen uutuus on että sääntöjä ei kerrota. Pitää siis päätellä mitä pitää saada aikaiseksi. Muistuttaa tältä osin ihan oikean elämän tehtäviä, missä pitää keksiä lopputulos samalla kun lopputulosta väkertää kasaan. Toki vuoropohjaisessa videopeliformaatissa aika paljon rajoittuneempaa mitä voi tehdä.
Jallittelin 3 tasoa ja menee kategoriaan brain teaser pelit jossa hiukan ohjeita puuttuu.
Tämä näyttää hyvin kuinka sidottuja LLM mallit ovat training dataansa. Kun joku keksii uuden tehtävän jota ei ole olemassa datassa nämä “huippuälykkäät” mallit putoavat jonnekin esikoulaisen alapuolelle.
Mielenkiintoinen kirjoitus entiseltä kollegalta @Markus_Hav:ilta (pingaan jos käytkin vielä foorumilla! ).
Markus uskoo Euroopan etuihin tekoälyskabassa perustuen Euroopan insinöörikulttuuriin ja lahjakkuuksiin.
Lainaus:
I fundamentally believe the EU is the best place in the world to do this right now, here is why:
We build for longevity, not just hype. European engineering culture is rooted in building secure, robust, and sustainable systems. When you are dealing with massive agent orchestrations, reliability and trust are not nice-to-haves. They are the entire foundation.
The talent pool is quietly world-class. We have brilliant builders who are focused on solving deeply complex architectural problems rather than just chasing the next quick funding round.
The great equalizer. I am honestly exhausted by the traditional mindset that others are always a step ahead of us. We have this habit of assuming Silicon Valley has a monopoly on magic, or, God forbid, that even our dear neighbors the Swedes are inherently better at scaling tech than we Finns are.
Yhtenä tärkeänä havaintona toi prosenttiluvun laskenta, eli 100% tosiaan asetettiin keinotekoisesti vastaamaan toiseksi parhaan ihmisen siirtojen määrää (jollen nyt väärin muista). Eli paras ihminen skorasi yli 100%. Lisäksi prosentti lasketaan logaritmisesti tms, eli alun jälkeen prosentti putoaa nopeasti kun siirtoja tekee enemmän.
Suosittelen kyseistä kanavaa muutenkin, aina tuoreimmat AI-uutiset pintaa syvemmältä ilman turhaa hypetystä.
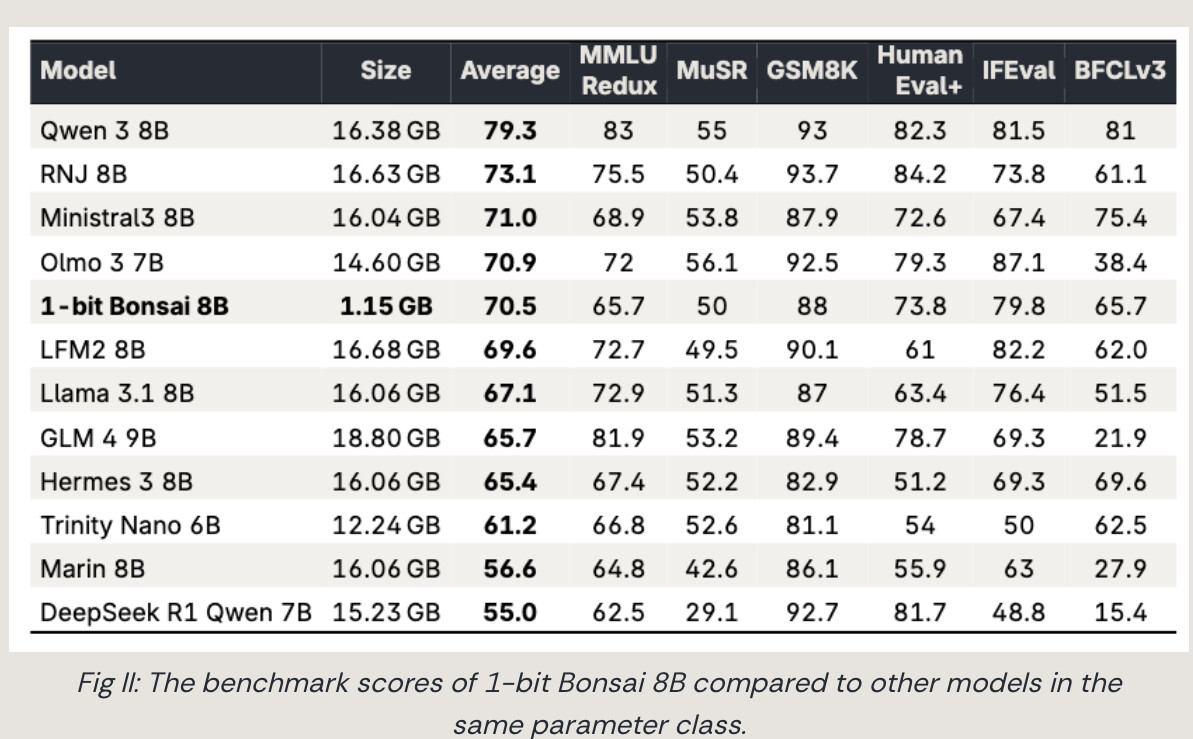
Tämän voisi luulla olevan aprillipila, mutta ei ole. Saimme vihdoinkin ensimmäisen aidosti toimivan 1-bitin kielimallin.
Ei se nyt tietenkään mikään ChatGPT 5.4 ole, mutta erittäin lupaava ja mielenkiintoinen avaus mallien pienimpään päätyyn:
1-bit Bonsai 8B is only 1.15 GB. At that size, it is small enough to fit on an iPhone 17 Pro. Relative to models with similar performance, that represents roughly a 14x reduction in model size. That reduction is not cosmetic. It changes what hardware can host serious intelligence.
Across devices, Bonsai also delivers major throughput gains. On an M4 Pro Mac, it runs at 131 tokens per second. On an RTX 4090, it reaches 368 tokens per second. On an iPhone 17 Pro Max, it runs at roughly 44 tokens per second.
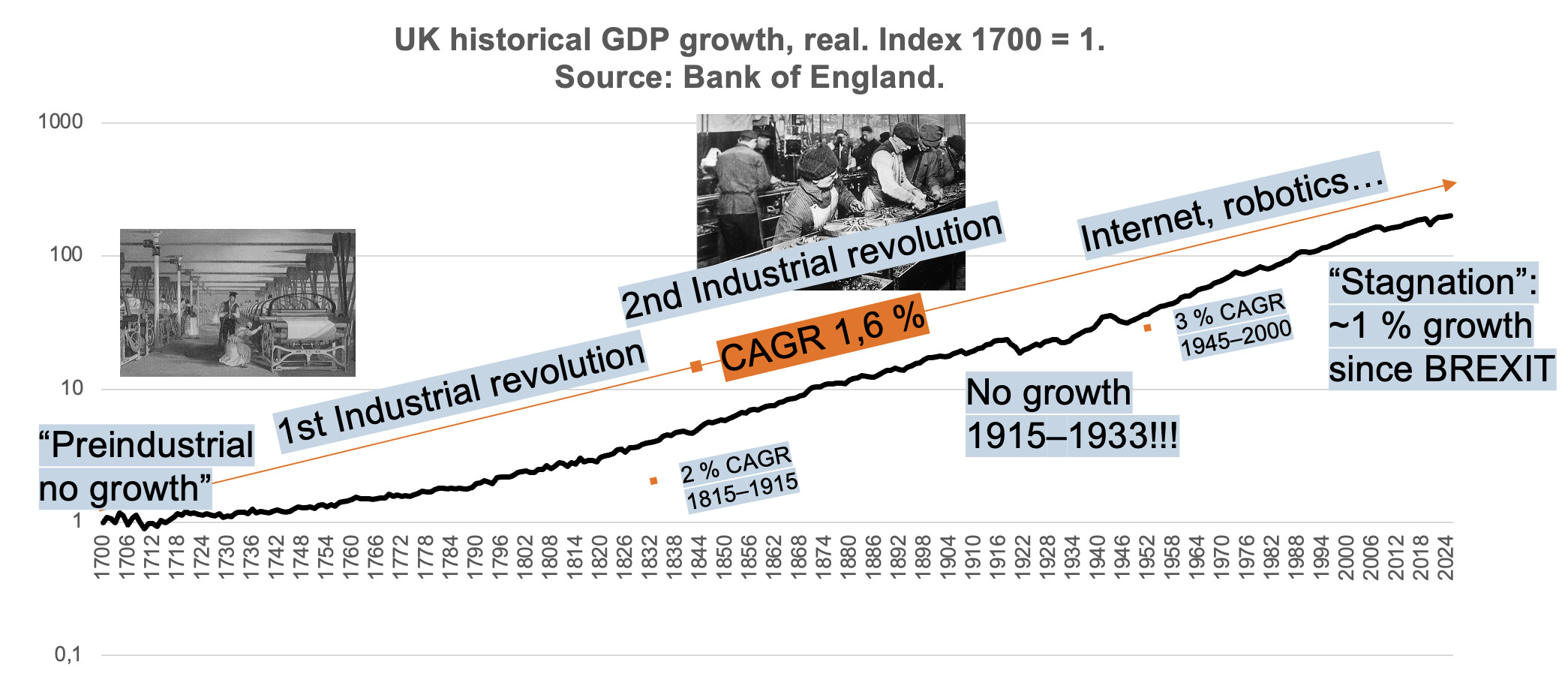
Valmistelen erästä makroesitystä ja ajattelin siinä käydä läpi kaiken muun ohella, mikä on oikeastaan “normaali” talouden kasvuvauhti. Jaan havainnon tähän ketjuun, koska juuri tällä hetkellä tekoäly ruokkii valtavasti mielikuvitusta talouskasvun kiihdyttäjänä (toki samaan aikaan myös talouden romauttajana).
Tässä on Iso-Britannian reaalisen BKT:n (se yleisin mittari, mistä luette uutisissa) kehitys vuosina 1700–2025.
Tälle ajanjaksolle mahtuu nykyihmiselle lähes käsityskyvyn ylittäviä teknologisia keksintöjä ja mullistuksia. Siis siinä mielessä, että nyt ne ovat niin arkipäivää ettemme välttämättä osaa täysin arvostaa niiden mullistavaa vaikutusta.
Esimerkiksi tekstiiliteollisuuden tuottavuuden kasvu eli kaikenmaailman kehruulaitteet, höyrykone ja rautatiet ensimmäisessä teollisessa vallankumouksessa. Samalla kauppa syveni ja globalisoitui. Sitten toisessa vallankumouksessa massatuotanto, standardoidut osat, mekanisaatiota, sähkö jne.
Tämän ajanjakson ensimmäisen puolen Iso-Britannia oli imperiumi valtavilla siirtomailla. Sillä oli maailman suurin ja mahtavin laivasto. Valtavat luonnonvarat siirtomaissa. Maailman syvin pääomamarkkina, mistä rahaa sijoitettiin ja lainattiin muualle maailmaan Venäjältä E-Amerikkaan ja Yhdysvaltoihin. Teknologinen johtajuus ja innovaatiot olivat maailman kärkeä.
Ja mikä oli esimerkiksi brittien nostalgisimman huippukauden 1815–1915 keskimääräinen BKT:n kasvu nopeus? 2 %.
Koko ajanjaksolla 1700–2025 kasvu on ollut… 1,6 %.
Miksi aina luulemme, että talouskasvu olisi normaalisti nopeampaa? Koska useimmat taloustietäjät ovat boomereita, ja tämä ei ole itsessään kritiikki vaan viittaan heidän nuoruuden aikaan. Talous kasvoi häkellyttävän kovaa toisen maailmansodan jälkeen, 2,6 % peräti vuodessa 1945–2000. Siksi heille monelle nykyinen 1 % kasvuvauhdin stagnaatio näyttää niin huonolta. Mutta on tuolla aiemminkin ollut jopa nollakasvun kausia.
Takaisin tekoälyyn. Kun miettii arvioita tekoälyn vaikutuksesta talouskasvuun, pitää todellakin uskoa että kaikki on toisin. Ehkä on, mutta niin oli ennenkin. Kun rautatiet tulivat, pelättiin ihmisten liiskaantuvan penkkeihinsä höyryjunan kovassa vauhdissa. Suuri John Keynes arveli aikoinaan työaikojen romahtavan tulevaisuudessa. On menty kuuhun, on porattu syvälle maaperään rouhimaan kultaa. On saatu lapsikuolleisuus laskemaan, on nostettu koulutustasoa valtavasti. Köyhyys on vähentynyt ja tämän päivän köyhinkin ihminen voi päästä sen tasoiseen lääketieteelliseen hoitoon, mistä 1800-luvun alun kuninkaallinen ei voinut edes haaveilla.
Tämä kaikki on tapahtunut 1,6 % keskimääräisellä talouskasvuvauhdilla. Tai tästä 1,6 % vauhdista huolimatta.
Claudelta tuli ratkaisu sulkea OpenClaw’t ja muut kolmannen osapuolen työkalut tilausmallin (Pro, Max jne) ulkopuolelle. Ainoa vaihtoehto on jatkaa käyttöä (käytön mukaan skaalautuvalla) API-taksalla.
Virallinen selitys liittyy kapasiteetin hallintaan, mutta laajemmassa kuvassa halu kerätä korporaatiokäyttäjiä omaan “ekosysteemiinsä” lienee myös yksi syy. Pelkkänä älybittiputken konehuoneena toimiminen open source -kielimallien kiriessä lähemmäs painaisi kateprossaa nopsaan alas ja kai väistämättömän listautumisen hintalappu ja uudet rahoituskierrokset muuttuisivat vähemmän houkutteleviksi.
Ymmärrän päätöstä ja arkipäivisin Claude Pro:n rajat tulevatkin kovin nopeasti vastaan. Meitä, jotka emme ole osanneet/uskaltaneet lähteä OpenClaw’n kaltaisten älyagenttien aktiivikäyttäjiksi, päätös ilahduttaa. Olemmehan mukavampia asiakkaita kuin käyttölimiittiä vastaan (teoriassa) 24h pyörivät agentit. Mitä päätös tekee Clauden maineelle OS-väen parissa? Hallaa, mutta tekoälykisan saturoituessa ne edullisetkin lounaat on nopsaan syöty ja edetään investointien rahastusvaiheessen, tavalla tai toisella.
Kielimallikisa on kuin seuraisi kilpajuoksua avaruuteen. Moniko kielimalliraketti kokee lopulta posahduksen matkalla ylös? No, jos raatoja tulee, ne ovat tässä kisassa onneksi vain korporaatioita.
New Yorkerilta tuli hurja(n pitkä) juttu vaihtoehtomies samista. Tässä muutama herkullinen nosto:
The specific concerns that led the board to fire Altman in 2023. Sutskever’s memos allege a pattern of deception about safety protocols. One begins with a list: “Sam exhibits a consistent pattern of . . .” The first item is “Lying.”
The superalignment team was publicly promised 20% of compute. People who worked on the team say actual resources were 1-2%, on the oldest hardware. The team was dissolved without completing its mission. When reporters asked to interview OpenAI researchers working on existential safety, a company representative replied: “What do you mean by ‘existential safety’? That’s not, like, a thing.”
After Altman’s reinstatement, the firm behind the Enron and WorldCom -investigations was hired to review the allegations. No written report was ever produced. Findings were limited to oral briefings.
In a tense call after his firing, the board pressed Altman to acknowledge a pattern of deception. “I can’t change my personality,” he said. A board member’s interpretation: “What it meant was ‘I have this trait where I lie to people, and I’m not going to stop.’”
In OpenAI’s early years, executives discussed playing world powers including China and Russia against each other in a bidding war for AI. The company’s own policy adviser: “We’re talking about potentially the most destructive technology ever invented — what if we sold it to Putin?” The plan was dropped after employees threatened to quit.
When Anthropic refused a Pentagon ultimatum to drop its prohibitions on autonomous weapons, Altman publicly claimed solidarity. But he’d been negotiating with the Pentagon for at least two days. That Friday, OpenAI announced a $50B deal integrating its models into military infrastructure.
Multiple senior Microsoft executives described the relationship as “fraught.” One: “He has misrepresented, distorted, renegotiated, reneged on agreements.”
Clauden February 2026 päivitys taisi törmätä vähän tämän kaltaiseen ongelmaan ja asiat menivät “kuten tietokonejutuissa yleensä”:
Since the February 2026 updates, Claude Code — Anthropic’s terminal-based AI coding assistant — has been exhibiting behaviors that make it genuinely unreliable for the kind of complex engineering tasks it was previously quite good at. We’re talking about refactoring large codebases, debugging multi-service architectures, generating boilerplate across many files, and maintaining coherent context over long sessions.
This isn’t a “the AI got lazy” complaint. There are specific, reproducible failure patterns that engineers across multiple communities have documented. Let’s break them down.
…
The Specific Problems Engineers Are Reporting
1. Context Degradation in Long Sessions
The most commonly reported issue is what developers are calling “context rot” — a phenomenon where Claude Code progressively loses track of earlier instructions, file states, and architectural decisions as a session grows longer.
Before February, Claude Code could reasonably maintain coherent reasoning across 40–60 tool calls in a single session. Post-update, many developers report meaningful degradation starting as early as 15–20 tool calls.
What this looks like in practice:
Claude suggests changes that contradict decisions made earlier in the same session
Previously edited files get re-edited with conflicting logic
Variable names, function signatures, and API contracts get “forgotten” and reinvented
The model starts hedging or asking for clarification on things it already established
2. Inconsistent Tool Use and Agentic Loop Failures
Claude Code’s power comes from its ability to use tools — reading files, running shell commands, editing code — in coordinated sequences. The February updates appear to have introduced instability in how the model chains these tool calls together.
Specific failure modes include:
Premature task termination (“I’ve completed the task” when it hasn’t)
Repeated tool calls in loops without making progress
Failing to read a file before editing it, producing hallucinated diffs
Shell command outputs being misinterpreted or ignored
This is particularly painful for teams using Claude Code in CI/CD pipelines or automated engineering workflows.
3. Degraded Performance on Multi-File Refactoring
Complex refactoring — the kind where you’re renaming a core interface and need to update 30+ files consistently — has become noticeably less reliable. Engineers report that Claude Code will:
Miss files that clearly need updating
Apply changes inconsistently (updating some call sites but not others)
Introduce syntax errors in files it touches
Fail to account for test files, configuration files, or documentation that reference the changed code
4. Increased Hallucination of File Paths and API Signatures
A subtler but deeply frustrating issue: Claude Code is more frequently hallucinating file paths that don’t exist and generating code that calls APIs with incorrect signatures — even when the correct signatures are present in files it has already read in the same session.
Why Did This Happen? What Anthropic Changed
Anthropic hasn’t published a detailed changelog explaining the behavioral shifts, which has added to developer frustration. Based on community analysis and Anthropic’s sparse communications, the February updates appear to have included:
Model weight updates to the underlying Claude 3.7 (or variant) powering Claude Code
Changes to the system prompt and tool-use scaffolding that governs how Claude Code orchestrates actions
Adjustments to context window prioritization — how the model weights recent vs. older context
The last point is particularly significant. It appears the model was tuned to weight recent context more heavily, which improves performance on short, focused tasks but actively hurts long-running engineering sessions where earlier context is critically important.
Anthropic has acknowledged “some performance regressions in agentic use cases” in a brief forum post, but has not committed to a specific fix timeline as of this writing (April 2026).
Mitä isommissa ja erilaisemmissa työnkuluissa näitä AI-agentteja käytetään, niin sitä tärkeämpää olisi pystyä takaamaan jonkinlaista taaksepäin yhteensopivuutta. Tietysti tämä on määritelmällisesti jokseenkin mahdotonta, koska AI-agentin / mallin toiminnalle ei sinällään ole täsmällistä ja selkeää speksiä, mitä vasten toimittaja voisi evaluoida mallin ja työkalujen toimintaa. Näin ollen mallin/työkalujen toimittaja ei voi testata, kykenevätkö malli ja siihen liittyvät työkalut samoihin asioihin, joihin mallin edellinen versio kykeni eri käyttötilanteissa.
Kuitenkin käyttäjän kannalta on sietämätön tilanne pidemmän päälle, jos päivitykset tulevat yllättäen ja pyytämättä kuin faksit eduskuntaan ja päivitysten yhteydessä joutuu rakentamaan agenttisia työnkulkuja välillä isostikin uusiksi. Jossain hello world -demokokeilussa tämä ei haittaa, mutta mitä pidemmälle asioita pyritään tekemään agenttien avulla autonomisesti, sitä fataalimpia tällaiset muutokset päivitysten yhteydessä ovat. Pahimmillaan isonkin firman toiminta voi pysähtyä kokonaan vähintään joksikin aikaa, jos on sattumalta saatu luoduksi riippuvuus juuri sen tyylisiin prompteihin ja työnkulkuihin, jotka hajoavat päivityksen yhteydessä ja AI-mallin toimittaja ei pysty lupaamaan edes aikaraamia, jonka puitteissa tilanne korjataan aiemmalle tasolle.
Jossain mielessä tuntuu siltä, että tässä AI-innostuksessa opetellaan tiettyjä insinöörityön opinkappaleita kantapään kautta uudelleen.
Kyllä tuo on täysin ratkaistu ongelma. Jos sulla on tilanne mikä pitää jäädyttää, niin sitten jäädytät sen mallin, etkä kytke agenttien toimintaa sellaiseen palveluun missä mallit ja niiden ympärille rakennetut telineet muuttuvat joka viikko. Mikäli haluat myöhemmin päivittää mallia tai huolehtia etteivät nämä jatkuvasti kehittyvät palvelut riko agenttejasi, niin voit myös aina rakentaa juuri sun tapaukseen soveltuvan agenttibenchmarkin ihan samaan tapaan kuin laadukkaassa koodissa on muutenkin yleensä valtavasti testejä ettei regressiota tapahdu. Tietty jos ostetaan aivotonta vibekoodausta kun firman on pakko olla muodikas tekoälyn käytössä niin sitten saadaan vibelaatua ja se kiireellä tehty agenttispagetti voi hajota ihan milloin tahansa.
Ilmeisesti ärtymystä aiheuttaa (ainakin tuohon kirjoitukseen tehdyn koosteen perusteella) se, että Pre-February -malliin ei noin vaan pääse palaamaan:
Q: Will reverting to an older version of Claude Code fix the issues?
A: Unfortunately, no. Claude Code’s behavior is primarily determined by the underlying model weights, which are server-side and not user-controllable. You cannot pin to a pre-February model version. This is one of the core frustrations engineers have raised.
Mutta ehkä toisissa yhteyksissä tuollainen freeze toimii paremmin. Tai sitten vaan blogiteksti sisältää huonolaatuisen koosteen tilanteesta.
Itse kun käytän arvosijoittajana Codexia (ei ole loputonta lompakkoa työnantajan VC-rahaa heittää Claudeen), niin tuntuu että aina kun avaan Powershellin, niin siellä odottaa uusi Codexin päivitys, mikä usein ihan mitattavasti muuttaa agenttien käyttäytymistä. Lisäksi uusia malleja lisätään ja vanhoja poistuu muutaman kuukauden välein ja niillä on usein eri vahvuudet. Esimerkiksi 5.2 on tietyissä tehtävissä parempi kuin 5.3 tai 5.4, joten malli pitää valita tehtävän mukaan. Olisi kyllä täysin pähkähullua heittää mitään kriittistä toimintoa noin volatiiliin ympäristöön. Aika moni firma kyllä kuitenkin tekee noin, mutta sillä tavalla ei voi rakentaa mitään aidosti kestävää ja sitten tapahtuu juuri kuvaamallasi tavalla, että tapahtuu joku päivitys mikä rikkoo hallitsemattomasti kaiken eikä edellistä tilaa kyetä enää palauttamaan.
Tämän takia avoimien painojen malleille on jatkossakin kysyntää, koska ne ovat ennustettavia. Otat vaikka Gemma 4 käyttöön, niin se pysyy samanlaisena maailman loppuun saakka tai kunnes migratoit agentit seuraaviin malleihin: