Samaa mieletä, että AGI ei ole lähelläkään.
LLM koodaa siten, että se osaa generoida seuraavan sanan, koska se ymmärtää kontekstin hyvin, pohjautuen sanojen yli 1000 ulotteiseen embedding avaruuteen.
Ihminen opettelee koodaamaan opettelemalla kielen käskyt, kuten for-looppi
Sama ero on muissakin asioissa eli kielimalli pohjautuu todennäköisyyteen.
Transformerin ydinhän on embedding avaruus. Periaatteessa mitä dataa vain voi tuoda tokeneiksi ja muuttaa takaisin.
Embedding avaruus ei sinänsä ole käytä sanoja, vaan se kuvaa ympäräröivän maailman asioiden suhteita vektoreilla.
Tällä menetelmällä saadaan ihmisen kaltaista toimintaa vaikka sen oppiminen ja ajattelu ei olekaan ihmisen kaltaista
Transformeria tai sen muunnoksia käytetään hyvin paljon kaiken datan käsittelyyn. Koko Multimodal ajettelu pohjautuu siihen, että samassa avaruudessa voi käsitellä usean tyyppistä dataa.
En tiedä mihin tämä viittaa, mutta Roboteissa ja autonomisissa autoissa käytetään Transformeria.
Samoin käsittääkseni DeepSeekissä käytetään Transfomer pohjaista, eli ovat tehneet omia virityksiä perusmalliin. Transformer-pohjainen viittaa Self Attention tyyppiseen embedding avaruuden käsittelyyn
JEPA sekä Large Concept Models mainitsin siksi, että Meta LeCunin johdolla pyrkii ihmisen kaltaiseen AI:n
JEPA on Self Superviced learning malli, jossa opetetaan x-encoder malli ennustamaan tietoa y-encoder mallin mukaan. Tämä siten että predictorissa on abstract representation space, joka pyrkii muodostamaan tiedon siitä, mitä konkreettista y-encoder esittää (kissa, koira jne.)
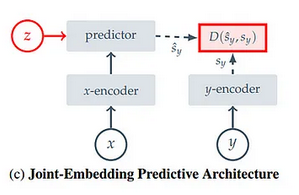
I-JEPA opettaa context encoderia targetin avulla. Koska predictorissa on abstrakti moniulotteinen avaruus, jossa muodostuu tieto kuvan kohteesta, ei kuvaa ennusteta pikselitasolla vaan ymmärretään objekti, jota generoidaan
V-JEPA on saman kaltainen videolle.
Kummatkin on rakennettu käyttäen useita ViT-malleja (Vision Transformer)
Large Concept Models (LCMs) LeCunn hakee saman kaltaista konseptia.
Koska ihminenkään ei lue kirjasta yksittäisiä sanoja, vaan lukee pidemmän pätkän ja sisäistää sisällön (Concept), pyrkii LCM toimimaan samoin
Eli pitkästä tekstistä tunnistetaan konsepteja. Koska konseptit ovat kokonaisuuksia, voidaan niistä tuottaa lopuksi sitä kuvaava teksti eri lähtökohdista. Tai konseptista voi tuottaa kuvan jne.
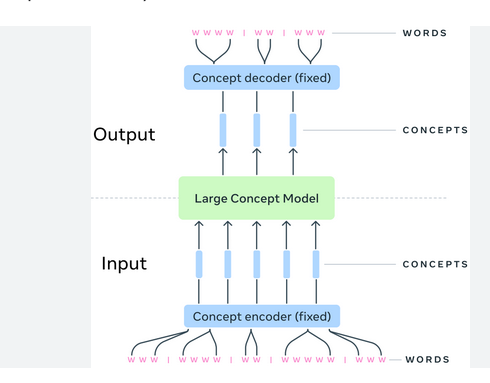
Myös LCM on toteutettu käyttäen Transformeria
Eli kun työstetään tekstiä, kuvia jne. LeCunn pyrkii taustalla tunnistamaan isompia konsepteja ja objekteja, joihin tekstin ja kuvien ym. generointi perustuu
AGI:sta.
AGI:sta nousee aika ajoin hype. Usein tämä aiheutuu siitä, että jokin toimii kuten ihminen.
2 vuotta sitten nousi AGI-hype, kun ChatGPT vastasi kuten ihminen.
Toisille S-ryhmän ruokarobotit tuovat uskoa AGI:n toteutumiseen tai tällä hetkellä DeepSeekin hienot LLM:n tehostamisideat.
Vaikka mitään uutta merkittävää AGI:n mahdollistavaa muutosta AI-malleihin ei ole tullut








